


Системный Блокъ
20 ноября 2020

18 марта 2020
Новый мобильный Google Translate: одинокая колбаса больше не увидит сельдерей
В прошлом году Google внес изменения в функцию камеры в своем мобильном приложении Translate. Новая версия приложения поддерживает 60 новых языков и лучше фиксирует переведенный текст на изображении; кроме того, компания обновила основные модели перевода, в некоторых случаях сократив частотность ошибок на 85 %.
Все это на радость постоянным пользователям приложения Google Translate, которым функция камеры нужна, чтобы переводить, например, меню или дорожные знаки. Ранее неоднократно звучали жалобы на некачественный перевод, нестабильную работу приложения и ограниченное число языков.Теперь поводов для недовольства должно стать меньше.
Как это работает?
Google наконец-то добавил в приложение свою систему нейронного машинного перевода (ранее она была доступна только в веб-версии Google Translate). Благодаря возможностям Google Lens приложение распознает текст и переводит его на целевой язык в режиме реального времени.
Сервис Google Lens был создан для мгновенного распознавания и обработки информации с изображений. Интеграция с ним позволяет Google Translate переводить как ранее сделанные фотографии, так и текст на незнакомом языке, который еще не сфотографирован, — достаточно просто навести на него камеру. Перевод можно прослушать, причем система маркером выделит для пользователя слово, которое читает прямо сейчас.
Куда теперь можно поехать, не зная языка?
Новая версия теперь поддерживает африкаанс, арабский, бенгальский, эстонский, греческий, хинди, игбо, яванский, курдский, латинский, латышский, малайский, монгольский, непальский, пушту, персидский, самоанский, сесото, словенский, суахили, тайский, вьетнамский, валлийский, коса, йоруба и зулу — всего поддерживаемых языков более 80. Google Translate также автоматически определит язык текста, что весьма полезно для путешествий в регионах, где распространено несколько языков. Путешествуем смело!
София Люба


Как накраудсорсить автобус
Жители большинства городов мира, особенно крупных, привыкли к тому, что общественный транспорт работает таким образом: человек приходит на специально определенное место и садится на определенный вид транспорта. Транспорт доставляет его в другое определенное место, где поездку можно прекратить. Но это возможно только если создана система тех самых определенных мест и видов транспорта — то есть остановок и маршрутов, по которым этот транспорт ходит. Согласитесь, это применимо к любым видам, будь то самолеты (хотя не очень-то он и общественный), паромы или автобусы.
Автобусы и война
Есть и особые случаи. Ливан — страна Ближнего Востока, расположенная на побережье Средиземного моря. С 1975 по 1990 годы, целых 15 лет, здесь бушевала гражданская война, которая оставила после себя полностью уничтоженную систему автобусного сообщения внутри страны и крупных городов. Прошло уже почти тридцать лет с момента установления мира, но в столице страны Бейруте вы не найдете ни одной автобусной остановки.
Несмотря на высокую популярность сервисов такси и частных авто (которые вносят немалый вклад в загазованность воздуха в городе), автобусы все же есть. Другое дело, что неместному жителю чрезвычайно сложно будет разобраться в системе, которая работает без четких ориентиров и схем. Автобусы в Бейруте работают так: вы должны знать, куда едет вот этот самый маршрут, и если он вам подходит, остановить нужный вам автобус небрежным взмахом руки в любом удобном месте. Легко сказать… Честно говоря, с точки зрения европейца, проще взять такси. Судя по наводненным желтыми машинами улицам, эту точку зрения разделяют многие.
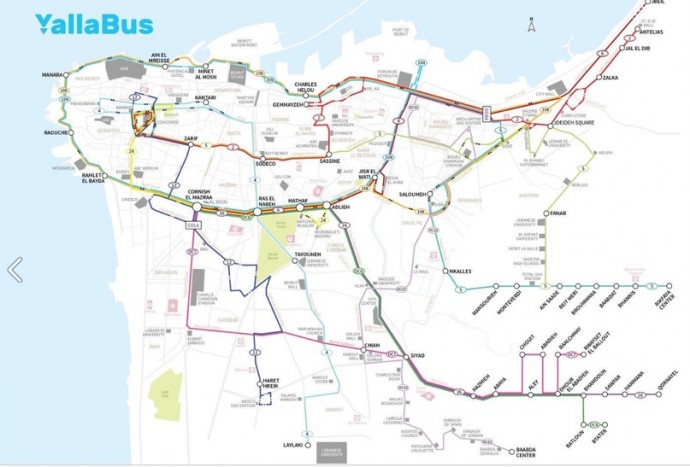
Связать водителя и пассажиров: YallaBus
Группа студентов из Американского университета Бейрута взялась исправить ситуацию с общественным транспортом в городе. Конечно, речь не идет о запуске собственных маршрутов — но о документировании уже существующих. Для этого использовались данные GPS и наблюдения волонтеров, и в результате команда, давшая своему продукту название YallaBus, получила примерную схему маршрутов городских автобусов Бейрута. Основываясь на ней, разработчики хотели «соединить» водителей автобусов и потенциальных пассажиров, показывая последним виртуальные места остановок, где проще всего поймать автобус, а первым — места сосредоточения пассажиров, которые хотели бы воспользоваться услугами автобуса.
Целью проекта было не создать новую сеть транспорта, а извлечь максимум из уже существующей. Со временем на месте наиболее часто используемых зон для посадки и высадки можно было бы поставить настоящие остановки. К сожалению, сейчас проект выглядит замороженным, но хочется надеяться, что это временно.
Автобусные покатушки с GPS
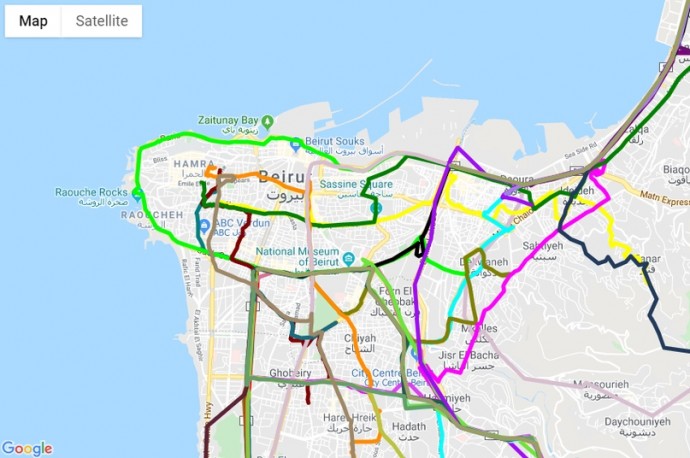
Похожий проект Bus Map Project был основан двумя ливанцами в 2016 году, и также собирает информацию о маршрутах автобусов, в основном самым простым способом — волонтеры проекта ездят на автобусах и записывают GPS-трек перемещения. Bus Map Project имеет более обширную историю, будучи основанным на работе и увлечениях разных людей — урбанистов, журналистов, ГИС-специалистов — только относительно недавно собравшихся вместе. Участники проекта ведут блог (правда, не весь он на английском), из которого можно узнать о последних новостях. В этом году участники проекта также сделали печатную карту маршрутов автобусов, которую старались распространять по мере возможности.
В одном из постов блога Bus Map Project интересно характеризует транспортную систему Ливана как «сеть из сетей» (network of networks), части которой могут принадлежать государству, муниципалитету, компаниям или вообще являться семейным бизнесом, могут работать только на одном маршруте или сразу на нескольких…
Еще одна частая проблема в попытке картографировать маршруты общественного транспорта (возможно, присущая странам Ближнего Востока) — место здесь не всегда имеет четкую привязку, вроде координат или номеров домов, а чаще описывается особенными деталями и признаками. Нет смысла искать дом по адресу, если ими все равно никто не пользуется, гораздо быстрее найти место по его описанию.
Из-за таких особенностей Bus Map Project часто подчеркивает, что все собранные ими данные не являются полными и полностью достоверными — всегда есть чем их улучшить, к чему они и приглашают всех заинтересовавшихся.
Пока что работы в этой области в стране хватит и на несколько проектов, так как государство не проявляет особого интереса к формированию централизованной сети общественного транспорта или хотя бы её документированию. Инициатива исходит исключительно от самих жителей.
Нелли Бурцева
Вавилонская нейросеть для многоязычного перевода
Практически все системы нейронного машинного перевода создавались для одной языковой пары — обработать несколько языковых пар, не изменяя базовую модель НМП, было невозможно.
В 2016 г. исследователи создали такую модель: они объединили одноязычные модели в одну структуру и добавили в начало исходной последовательности специальный символ, чтобы указать требуемый язык перевода. Все остальные части системы, такие как кодировщик (энкодер), декодер, механизм внимания и общий словарный запас модели остались без изменений.
Структура такой многоязычной модели идентична системе нейронного машинного перевода Google (GNMT), но в некоторых экспериментах к ней были добавлены прямые соединения между уровнями энкодера и декодера. Чтобы использовать многоязычные данные в рамках одной системы, специалисты предложили изменить входные данные и добавить в начале исходного предложения специальный токен, указывающий язык, на который должен быть осуществлен перевод. Например, при переводе в паре английский→испанский
How are you? -> ¿Cómo estás?
нужно внести следующее изменение:
How are you? -> ¿Cómo estás?
чтобы показать, что целевой язык (язык перевода) — испанский язык. Исходный язык не указывается — модель учит это автоматически. После добавления токена к исходным данным модель обучают на всех многоязычных данных, состоящих из нескольких параллельных корпусов одновременно. Чтобы решить проблему перевода неизвестных слов и ограничить словарный запас для эффективности вычислений, применялась общая модель в 32 тыс. слов для всех исходных и целевых данных.
Модели могут включать один или несколько исходных или целевых языков. Разработчики рассмотрели три случая: несколько исходных языков и один язык перевода, один исходный язык и несколько языков перевода, несколько исходных и несколько языков перевода.
Несколько исходных языков и один язык перевода
Это самый простой способ объединения языковых пар. Поскольку существует только один целевой язык, не нужно вводить дополнительный токен. Провели три группы экспериментов: для пар немецкий → английский / французский → английский, японский → английский / корейский → английский, испанский → английский / португальский → английский. Все модели многоязычных и одноязычных пар имели такое же количество параметров, как и базовые модели НМТ, обученные на одной языковой паре. Во всех экспериментах многоязычные модели превзошли базовые одноязычные системы, несмотря на некоторые недостатки в отношении количества параметров, доступных для языковой пары. Объяснить такой успех многоязычной НМТ можно еще и тем, что в модели было представлено больше данных для английского языка и что некоторые исходные языки принадлежат к одним и тем же языковым группам.
Один исходный язык и несколько языков перевода
Здесь провели три группы экспериментов, очень похожих на эксперименты из предыдущего пункта, добавив в начало исходного предложения токен, указывающий на целевой язык. Результаты показали, что многоязычные модели сопоставимы с базовыми моделями и в некоторых случаях превосходят их (значительное превосходство по шкале BLEU получили, например, для языковой пары английский → испанский).
Несколько исходных языков и несколько целевых языков
Самый сложный случай. Поскольку задано несколько целевых языков, к началу исходного предложения необходимо добавить токен для целевого языка. Эксперименты показали, что многоязычные модели с тем же объемом словаря, что и одноязычные, довольно близки к базовым показателям — средняя относительная потеря оценки по BLEU во всех экспериментах составляет всего около 2,5%.
Проводились и более крупные эксперименты — разработчики попытались объединить 12 рабочих языковых пар в единой многоязычной модели. Многоязычная модель потребовала меньше времени и вычислительных ресурсов на обучение, чем объединенные одноязычные модели, но больше, чем стандартная одноязычная модель. Такая многоязычная модель обрабатывает в 12 раз меньше данных, чем стандартная модель, поэтому она переводит в среднем хуже отдельных (от 5,6% до 2,5% потерь по BLEU в зависимости от размера), тем не менее, её результаты признаны удовлетворительными.
А что, если смешать языки?
После экспериментов с несколькими парами исходных или целевых языков исследователи задумались, что происходит, когда языки смешиваются на входе или на выходе. Может ли многоязычная модель успешно обрабатывать многоязычные входные данные (переключение кода) и что получится, если её запустить со смешением двух токенов для целевого языка?
Чтобы найти ответ, они провели дополнительные эксперименты и установили, что многоязычные модели способны справиться с переключением кода исходного языка в середине предложения. Например, смешивание японского и корейского языков в исходном коде во многих случаях приводит к правильным переводам на английский, что подтверждает: модель может обрабатывать переключение кодов, хотя в обучающих данных таких примеров переключения кодов не было. Интересно, что смешанный перевод немного отличался от переводов отдельных примеров на разных языках на один исходный язык.
Эксперименты же с целевым языком продемонстрировали менее любопытные результаты. В зависимости от определенных параметров модель переводит исходное предложение либо на смесь языков, либо полностью на один из целевых языков с неестественными для него характеристиками (например, порядок слов).
Так откуда разговоры об интерлингве?
Объединив несколько языковых пар в одной модели, разработчики Google получили неожиданный и очень интересный результат: модель научилась переводить в языковых парах, на которых она не обучалась. Например многоязычная модель НМП, использующая примеры языковых пар португальский → английский и английский → испанский, может генерировать допустимые переводы для языковой пары португальский → испанский, даже не используя данные для этой языковой пары. При этом машина больше не переводит через английский («язык-мост»), а использует общие семантические представления между языками. Такой перевод без обучения (zero-shot translation) модель может выполнять только между языками, которые она в определенный момент обучения рассматривала отдельно как исходный и целевой языки.
Больше всего разработчиков удивило, что необученные модели оказались способны выдавать перевод приемлемого качества. Еще бы — ведь изначально это вообще казалось невозможным! Они предположили, что такой эффект возможен потому, что единая структура позволяет модели изучать форму interlingua между всеми этими языками — т.е. модель оказалась способна выявлять общие семантические слои для разных языков и находить им соответствия.
В эксперименте, описанном выше, перевод производился между языками, принадлежащими одной языковой семье (испанский и португальский), и исследователи заинтересовались, насколько хорошо работает перевод без обучения для менее родственных языков. Они сравнили с переводом через английский язык переводы без обучения в паре испанский → японский, использовав свою крупную модель (испанский и японский языки могут рассматриваться как совершенно не связанные). Как и ожидалось, перевод без обучения сработал хуже, и качество перевода упало сильнее (по BLEU — примерно на 50%), по сравнению со случаем для более родственных языков.
Несмотря на снижение качества, исследователи пришли к выводу о том, что такой подход позволяет осуществлять перевод даже между несвязанными языками. Говорить о том, что существует универсальный язык, через который Google научился переводить тексты с любых языков, пока рано. Но возможно Google подобрался еще на шаг ближе к тому, как переводит человек.
Александра Опанасенко

Слепнущие нейросети
31 октября на Международной конференции по компьютерному зрению в Сеуле (ICCV 2019) было представлено исследование «Что не может создать GAN (генеративно-состязательная сеть)».
Дэвид Бау, сотрудник Лаборатории компьютерных наук и искусственного интеллекта (CSAIL) Массачусетского технологического института, вместе с коллегами исследовали характеристики данных, которые чаще игнорируются системой машинного обучения.
GAN и другие нейронные сети не только похоже обнаруживают шаблоны в данных, они также могут игнорировать схожие объекты. Бау и его коллеги обучали различные типы GAN на изображениях объектов внутри и снаружи зданий. Независимо от того, где были сделаны снимки, GAN постоянно опускала важные детали: людей, машины, вывески, фонтаны и предметы мебели, даже когда эти объекты заметно выделялись на изображении.
В процессе работы исследователи отметили также, что люди на изображениях могли исчезать выборочно. Иногда они превращались в кусты, а порой и вовсе растворялись в зданиях на заднем плане изображения.
Извини, человек, мне лень
Ученые предположили, что виной всему «лень» алгоритмов. Хотя целью GAN является создание убедительных образов, она может выучить, что легче воспроизводить здания и ландшафты и системно пропускать более трудные объекты, например, людей и автомобили. Ведь создать реалистичное человеческое лицо тяжело, и это получается редко. А за нереалистичные изображения GAN получает штраф — такова природа генеративно-состязательного обучения, в котором одна сеть должна убедить другую, что изображение хорошее. В итоге генеративная часть сети решает «не связываться» с этими сложными объектами и просто убирает их.
Исследователи давно знают, что GAN имеют склонность игнорировать некоторые статистически значимые детали, им легче генерировать здания и ландшафты, упуская более мелкие детали. Но это может быть первым исследованием, которое покажет, что современные GAN могут систематически опускать целые классы объектов в изображении.
Поскольку инженеры используют GAN при создании синтетических изображений для обучения автоматизированных систем, таких как беспилотные автомобили, существует опасность того, что люди, знаки и другая важная информация могут оказаться в «слепом пятне». Поэтому важно не только оценивать результат работы нейросети, но и понимать, как устроена сама модель.
Источник: Visualizing an AI model’s blind spots












