Системный Блокъ
18 марта 2020
Google-проповедник, гендерные стереотипы и развитие ИИ: интервью с разработчиком Googlе-Переводчика
Некоторое время назад Google Переводчик при попытке перевести определенные буквосочетания на суахили или маори выдавал пугающие религиозные пророчества. Кликбейт-сайты выдвигали предположения о заговоре, но на самом деле оказалось, что дело было всего лишь в особенностях обучающих датасетов — машинный перевод основывался на религиозных текстах и в сложных случаях обращался к привычным паттернам.
Эта ситуация в очередной раз породила волну обсуждений о сложностях машинного перевода. Тем не менее, как рассказал технический директор Google Translate Макдафф Хьюз (Macduff Hughes) изданию The Verge, именно возможность машинного обучения делает инструменты перевода Google такими успешными. Доступный, простой и быстрый перевод стал одной из тех привилегий XXI века, которую мы воспринимаем как что-то само собой разумеющееся, однако это стало возможным только благодаря искусственному интеллекту (ИИ).
В 2016 году Переводчик перешел с метода, известного как статистический машинный перевод по фразам, на метод, в котором задействованы нейросети. Старая модель перевода, когда текст переводился по одному слову, выдавала много ошибок, так как система не учитывала грамматические нормы, например времена глаголов и порядок слов. Новая же модель переводит предложение за предложением, а значит, учитывает чуть более широкий контекст.
«В результате мы получаем язык, который звучит естественнее, с более плавными переходами», — отмечает Хьюз, и обещает, что Google Переводчик ожидают еще большие положительные изменения. Скоро он сможет различать стили речи, (использует говорящий формальную лексику или сленг?), и чаще предлагать несколько вариантов формулировок.
Переводчик — это репутационно полезный для Google проект, который, как многие заметили, является для компании своего рода прикрытием применения искусственного интеллекта для спорных и неоднозначных целей, к примеру, военных разработок. Хьюз рассказывает, зачем компания продолжает поддерживать этот сервис, а также объясняет, как собираются решать проблему стереотипов при использовании данных для обучения искусственного интеллекта.
Интервью с Макдаффом Хьюзом
Главным нововведением в последней обновленной версии Переводчика стали гендерно обусловленные варианты перевода. Что сподвигло вас к таким изменениям?
Мы исходили из двух дополняющих друг друга факторов. Первый — обеспокоенность социальными предрассудками, которые встречаются во всех разработках с использованием машинного обучения и ИИ. Продукты и сервисы, использующие алгоритмы машинного обучения, отражают гендерные стереотипы, которые содержатся в обучающих данных, а те, в свою очередь, отражают социальные предрассудки, усиливая их и даже преувеличивая. Этой проблемой обеспокоены не только в Google, но и во всей индустрии. Мы, как любая компания, хотим занимать лидирующие позиции в решении этих проблем и мы знаем, что Переводчик тоже не идеален, особенно когда речь идет о гендерных стереотипах.
Классический пример стереотипного мышления: врач — мужчина, медсестра — женщина. Если такие предубеждения встречаются в языке, тогда и модель перевода запомнит их и будет распространять. Если, к примеру, в 60-70% случаев профессия относится к мужчинам, тогда система перевода может запомнить это и в 100% случаев будет указывать её как мужскую. Нам нужно бороться с этим.
Многие наши пользователей изучают языки и хотят понимать, какие существуют варианты выражения мыслей и какие при этом могут быть нюансы. Мы давно пришли к важности демонстрации нескольких вариантов перевода, и это тоже повлияло на наш гендерный проект. Нельзя точно сказать, каким образом стоит решать такие проблемы. Нельзя просто предлагать варианты в соотношении 50/50 или давать произвольный вариант (в случае, когда мы апеллируем к гендеру в переводе), правильней будет давать пользователям больше информации для выбора. Показать, что существует более одного варианта перевода данной фразы на другой язык, и отметить, какие существуют различия между предложенными вариантами. В переводе довольно много спорных культурных и языковых моментов; мы хотим хоть как-то решить проблему гендерных стереотипов и тем самым улучшить качество работы Переводчика.
Какова следующая проблема, связанная с предрассудками и нюансами перевода?
У нас есть три значительные инициативы. Первая — продолжать работу над проектом, который мы только что с вами обсуждали. Мы уже запустили перевод полных предложений с учётом гендерных факторов, но пока только с турецкого языка на английский. Далее мы хотим улучшить качество их перевода и подключить другие языки к данному проекту. Для некоторых языков мы завершили перевод отдельных слов.
Вторая инициатива касается перевода целых документов. В данном случае проблема предрассудков также существует, но она должна решаться иным образом. Например, возьмем статью из Википедии о женщине и переведем ее с другого языка, в котором нет категории рода, на английский. Вероятнее всего, большинство местоимений переведутся на английский как «он» и «его». Каждое предложение статьи переводится отдельно от других, и, если в тексте на исходном языке нет четких указаний на гендер, то с большей долей вероятности в переводе по умолчанию появятся местоимения, относящиеся к мужскому роду. Сегодня особенно оскорбительно использовать слово в неправильном роде, но решение этой проблемы требует абсолютно иного подхода, нежели мы использовали ранее. В нашем примере проблема решается обращением к контексту, остальной части документа. И эту проблему предстоит решить инженерам и исследователям.
Третья инициатива посвящена гендерно-нейтральным языковым конструкциям. Сегодня мы живем в самый разгар культурной нестабильности, отражающейся не только в английском языке, но и во всех языках, имеющих гендерно-окрашенные слова. В современном мире формируется движение за создание гендерно-нейтрального языка, и в связи с этим к нам поступает множество заявок от пользователей с вопросом, когда мы начнем его внедрять. Частый пример, который приводят в связи с этим, — использование в английском языке местоимения «они» в единственном числе. Вариант использования «они» по отношению к человеку в противовес местоимениям «он» или «она» очень популярен, хотя и не используется в учебниках и в стандартах. Такая же ситуация наблюдается в испанском, французском и многих других языках. Правила меняются с такой скоростью, что даже экспертам сложно уследить за всеми изменениями.
Любопытная ситуация произошла в прошлом году с Google Переводчиком, когда люди обнаружили, что при введении выдуманных бессмысленных слов он выдавал фрагменты религиозных текстов. Люди стали выдвигать фантастические теории на этот счет. Что вы предприняли по этому поводу?
Я не удивился, что это произошло, но меня поразило то, какой интерес это вызвало у пользователей. Стали появляться разные теории заговора — якобы Google зашифровал загадочные послания о космических пришельцах, тайных религиозных культах… На самом деле эта ситуация иллюстрирует основную проблему моделей машинного обучения, когда в ответ на ввод непредусмотренных данных система реагирует непредвиденным образом. Проблема, над которой мы работаем, заключается как раз в том, чтобы в ответ на бессмысленный запрос система не выдавала ничего осмысленного.
Но почему это произошло? Я не помню, чтобы вы когда либо озвучивали объяснение произошедшего.
Обычно это случается потому, что при обучении модели языку, на который вы переводите, в качестве обучающих данных используется большое количество религиозных текстов. Для каждой языковой пары, которая сейчас у нас имеется, мы используем в процессе машинного обучения всю доступную в Интернете информацию. Поэтому типичное поведение модели, столкнувшейся с непонятной фразой — подбор самого близкого варианта из обучающих данных. В ситуации с редкими языками, на которые в интернете очень мало переведенных текстов, модель чаще всего выдает фразы религиозного толка.
Для некоторых языков первым переведенным документом, который мы нашли, была Библия. Мы берём всё, что можем найти, и обычно всё в порядке, но если вводить бессмыслицу, результат часто бывает именно такой. Если бы основными переведенными документами были юридические документы, то модель бы выдавала термины из юриспруденции, если бы это были руководства по управлению самолетом, то выдавались бы летные инструкции.
Это невероятно. Напоминает то, как Библия короля Джеймса повлияла на становление английского языка. Мы и сегодня используем многие фразы, взятые из этого перевода Библии 17-го века. Что-то похожее происходило с Google Переводчиком? Много ли необычных источников и фраз используется в обучающих базах?
Да, иногда нам попадаются необычные фразы из интернет сообществ, например, сленг с игровых форумов и сайтов. И такое бывает! Увеличивая количество языков, мы собираем более разнообразные данные для обучения, и да, иногда на просторах интернета встречается довольно занимательный сленг. Но, боюсь, пока не могу припомнить ничего определенного.
Итак, Google Переводчик особенно интересен тем, что, в отличии от ИИ, о котором ведутся споры, как и где его можно применять, все единодушны во мнении, что перевод — вещь полезная и относительно беспроблемная. Что, на ваш взгляд, мотивирует Google вкладывать средства в перевод?
Наша компания ставит перед собой довольно идеалистические цели. Я считаю, что команда разработчиков Google Переводчика еще большие идеалисты. Мы усердно работаем, чтобы сказанное вами было правильно понято. И именно поэтому так важно бороться с предрассудками и исправлять неверный перевод, который может принести вред.
Но зачем Google в это инвестировать? Нас часто об этом спрашивают, и ответ довольно прост. Наша миссия заключается в том, чтобы систематизировать всю информацию в мире, и сделать её доступной для каждого, а мы еще очень сильно далеки от достижения «доступности каждому». И пока большая часть жителей планеты не сможет получить доступ к онлайн информации, ее нельзя считать всемирно доступной. Чтобы выполнить основную миссию компании, Google должен решить проблему перевода, и я думаю, что основатели понимали это еще десятилетие назад.
А вы считаете возможно решить проблему перевода? Недавно в журнале The Atlantic вышла статья известного профессора-когнитивиста Дугласа Хофштадтера, в которой он отмечает «ограниченность» Google Переводчика. Что вы можете ответить на его критику?
То, на что он указал, было справедливым, и это правда так. В работе Переводчика есть эти проблемы. Но пока они для нас не на первом плане, потому что при переводе они выявляются в очень малом проценте случаев. Если мы возьмем типичные тексты, которые люди обычно переводят, там эти проблемы возникают крайне редко. Но он прав: чтобы на самом деле решить проблему перевода и позволить машинному переводу достичь уровня опытного переводчика, необходимы серьезные технические усовершенствования. Обучаясь только на примерах параллельных текстов, невозможно узнать о нескольких оставшихся процентах случаев.
Ведь как уже очень давно говорят, перевод — это основная проблема ИИ. Поэтому, чтобы полностью решить проблему перевода, необходимо полностью решить проблемы ИИ. И я согласен с этим. Однако я считаю, что можно решить очень большой процент этих проблем, чем мы сейчас и занимаемся.
Инесса Анохина, Наталья Пак


Машинное обучение и Data Science похожи на ядерную физику в начале 50-х или кибернетику в 60-е. Мечтают делать многие, понимают немногие, делают — совсем немногие. Главная преграда — математика. Все эти «линейные регрессии», «градиентные спуски» и «дифференцируемые функции» пугают, особенно если вы не открывали учебники со школы. Да и если открывали — матан и линал все равно немного бросают в дрожь. А без математики в Data Science никуда.
Простой пример — производные. В школе их изучение обычно привязывают к физике. Помните, там скорость разных едущих/бегущих/летящих объектов вычислялась как производная от расстояния, а ускорение — как производная от скорости... Так вот, в Data Science производные используются в обучении нейросетей. Чтобы нейросеть всё лучше переводила тексты или распознавала котиков на фото, применяют алгоритм «обратного распространения ошибки» и тот самый «градиентный спуск». А в его основе — как раз расчет производных!
Вот только в Data Science производные посложнее, чем в школьной программе. В школе нужно было найти точку с нулевой производной на двумерном графике — а здесь многомерные гиперплоскости… Разобраться в этом самому непросто. Гораздо проще понять математику в основе нейросетей, расспрашивая опытного дата-сайнтиста. Такая возможность будет сегодня в 20:00 — наши партнеры OTUS проведут бесплатный вебинар «Математика в Data Science».
Регистрация: https://otus.pw/Rkl4/
Что там будет?
На вебинаре вам расскажут:
— какая математика нужна для Data Science, а без чего можно обойтись
— с чего правильно начинать обучение, чтобы было понятно и не страшно
— как развиваться в Data Science и строить свою карьеру
Кто ведет?
Курс ведёт Пётр Лукьянченко — преподаватель высшей математики в НИУ-ВШЭ с 10 летним стажем и data-саентист. Учился в Лондонской школе экономики, работал Team Lead Analytics в Lamoda, занимался анализом экспериментальных данных в научной организации.
Что будет за вебинаром?
Если вебинар вам понравится, вы сможете подключиться к обучению на основном курсе «Математика в Data Science». У курса есть базовая версия для новичков — и продвинутая, для тех, кто уже начал разбираться в Data Science, но хочет прокачаться. Курс платный, ознакомиться с программой можно по ссылке: otus.pw/vbZ5/

Сегодня 160 лет Антону Павловичу Чехову. За несколько месяцев до смерти Чехов сказал Бунину, что читать его будут «лет семь». А в итоге оказался звездой мировой литературы, вместе с Достоевским и Толстым. Чеховым вдохновлялись Джойс, Вирджиния Вулф и Бернард Шоу, его пьесы ставят по всему миру. В театре Чехов стал таким же новатором, как Эйнштейн в физике или Стив Джобс в мобильной электронике. Чехов переизобрел драматургию: в его пьесах часто нет главного героя, нет однозначно хороших или плохих персонажей, вообще — нет диктата автора. Автор рисует тонких, сложных, психологически нагруженных персонажей, а режиссеру достается свобода создавать из них самые разные сценические прочтения — вплоть до противоположных друг другу. Ничего подобного не было и не могло быть в пьесах драматургов до-чеховской поры, вроде Островского.
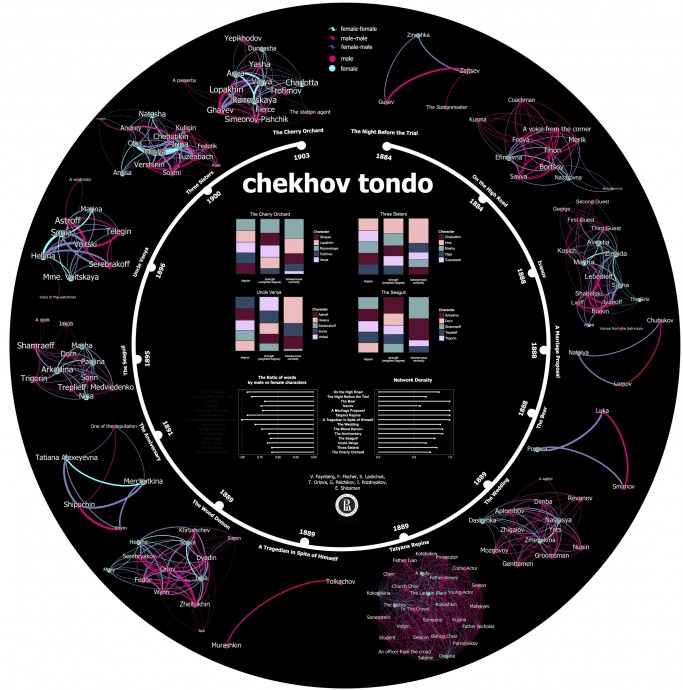
Цифровые методы пока что плохо приспособлены для исследования литературного творчества. Digital Literary Studies, цифровое литературоведение, делает свои первые шаги. Тем не менее первые робкие подходы к исследованию драматургии, и конкретно творчества Чехова, уже есть. Сегодня мы хотим поделиться работой русско-немецкой команды ученых, которая исследовала и визуализировала пьесы Чехова с использованием сетевого анализа (англ. network analysis, нем. Netzwerkanalyse).
Каждая пьеса — от ранних «На большой дороге» и «Ночи перед судом» до классических «Чайки», «Дяди Вани», «Трех сестер» и «Вишневого сада», ставших венцом чеховской драматургии, — представлена в виде социальной сети персонажей. Сети построены на основе разметки взаимодействия между героями. Сила взаимодействия (толщина связи в сети) пропорциональна числу диалогов двух персонажей. Цветами обозначен пол героев.
Также в центре этой визуализации приведена статистика. В столбцах показаны распределения центральностей персонажей в социальных сетях наиболее значимых Чеховских пьес (мы рассказывали о том, как измеряется центральность, вот здесь: https://vk.com/@sysblok-socseti-russkoi-dramy-chast-i..). Под столбцами — два графика: правый показывает плотность социальных сетей, левый — соотношение мужской и женской речи в пьесах Чехова.
Что дает такое представление? Во-первых, информация о центральностях персонажей подтверждает тезис об отсутствии главного героя в большинстве пьес. Центральности распределены равномерно, а в «Дяде Ване» и «Чайке» наиболее центральный персонаж меняется в зависимости от метрики.
Во-вторых, Чехов оказывается практически единственным классическим русским драматургом, у которого доля женской речи в пьесах сопоставима с мужской. У других крупных авторов пьес, например, Островского или Гоголя, мужчины говорят в разы больше, чем женщины. У Чехова же практически гендерный паритет.
В-третьих, мы можем проследить своеобразную эволюцию структуры Чеховских пьес. В 80-е годы, первый период взрослого творчества Чехова, испытываются разные конфигурации героев: от самых маленьких, на 2-3 персонажа, в небольших шуточных пьесах вроде «Медведя», «Предложения» или «Трагика поневоле», до нагромождения лиц и фигур в написанной не для сцены «Татьяне Репиной». К концу творческой биографии Чехова (условный период с 1895 по 1904) видна некоторая стабилизация: писатель оставил малые шуточные формы, но и не создает больше сценических толп. Его поздние пьесы — зрелые полновесные драматические произведения со сложными, но не переусложненными конфигурациями персонажей.
#philology@sysblok
От Ктулху до Человеколося: мифы в цифровой галактике
Чем человек отличается от животных? В отличие от других живых существ, человек способен передавать сложные знания, умения и навыки без непосредственной их демонстрации. Человек способен научиться чему-либо без непосредственного наблюдения благодаря способности к передаче информации.
Человек всегда стремился делиться своими знаниями о мире, используя различные средства презентации и репрезентации — устную речь, глиняные таблички, папирус, бумагу. Но в XV веке появился новый способ передачи информации, который был быстрее, дешевле и долговечнее: с появлением печатного станка передача информации стала принципиально иной. Можно выделить несколько этапов, которые изменили мир — это изобретение книгопечатания, радио, телевидения и интернета.
С каждым следующим шагом человечество становилось грамотнее, информация — доступнее, а каждый ее потребитель обретал все больше возможностей: если печатная книга просто позволяет читателю получить информацию, то интернет позволяет ему стать создателем собственной истории. Цифровая среда дает нам шанс осмыслить наше культурное наследие, сделать его частью повседневной жизни, дать мифам и легендам новую жизнь.
Цифровые медиа. Презентация и репрезентация культурного наследия.
Лев Манович утверждает, что цифровые медиа вбирают в себя языки искусства прежних эпох, язык массовой культуры, язык масс-медиа; новые форматы невозможны без старых. Однако цифровая среда принципиально отличается от информационного пространства прошлого: интерактивность в ней не просто возможна — она лежит в основе этой реальности. Интерактивность пользователя или интеракция с программным кодом или его написание рождает современный «просьюмеризм».
Термин «просьюмеризм» введенный Э. Тоффлером, означает, что активный пользователь с помощью «цифровых медиа» может самостоятельно конструировать собственные медиаобъекты, то есть заново репрезентировать то или иное явление с помощью цифровых программ. Такой пользователь производит то, что ему интересно, и он в силах это воспроизвести. Хорошим примером такой переработки можно назвать ролики YouTube с фанатским творчеством или инди-игры.
Когда «просьюмер» сталкивается с собственным запросом, он сталкивается с проблемой интермедиальности. Чтобы объяснить этот термин, используем определенные тезисы М. Маклюэна: эволюция медиаторов происходит при смене «холодных» (давно существующих) и «горячих» (недавно появившихся) медиа, при которой каждый новый медиатор в процессе развития общества «охлаждается».
Давайте попробуем разобраться, что это значит, на примере рассказа Говарда Лавкрафта «Зов Ктулху». Стоит сразу сказать, что существует гипотеза о прототипе Ктулху — это Тангароа, полинезийское божество моря; «холодный» миф разогревается, правда, пока оставаясь в текстовом пространстве. Как только читатели привыкли к Ктулху, рассказ тоже начал «остывать», периодически всплывая в других произведениях —- например, Анджея Сапковского («Башня шутов»), Стивена Кинга («Крауч-Энд») и Нила Геймана («Особое шогготское»).
Следующий этап — экранизации. Первый (фанатский) фильм про Ктулху вышел в 2005 году, потом Ктулху появился в 14 сезоне мультсериала «South Park». В то же время Ктулху не обошел и индустрию игр. Первая настольная игра по мотивам произведения вышла в 1981 году, в дальнейшем вышли уже такие компьютерные игры, где были отражены мифы Ктулху — это «Call of Cthulhu: Dark Corners of the Earth», «Cthulhu Saves the World», «Sherlock Holmes: The Awakened», «Terraria», «Call of Cthulhu (2018)».
Интермедиальность — это своего рода перевод, но не на другой язык, а в другую среду. Именно она позволяет нам создавать новые произведения по мотивам старых, используя возможности современного технического прогресса.
Как это выглядит на примере?
Кратос, главный герой серии игр God of War, прошел долгий путь — от титана (от имени которого образованы все слова с корнем -кратос, «власть»), слуги Зевса и помощника Гефеста, до антигероя, убийцы невинных и богоборца. Кратос вступает в схватку с богами, идет против своего господина — бога войны Ареса — и приносит людям надежду. В последней игре серии God of War (2018), вышедшей в позапрошлом году, вообще смешаны две мифологии — скандинавская и древнегреческая, что превращает игру в постмодернистский сюр.
Действие игры Banner saga происходит в вымышленном мире, основанном на скандинавской мифологии. На континенте, населенном людьми и варлами, появляются пришельцы-драги, от которых надо защищаться. Все расы созданы богами; все расы страдают от вечной зимы. Этот мир сложнее дохристианской Скандинавии, но в общем и целом своими очертаниями напоминает классический языческий миф. The Banner Saga получила высокие отзывы от критиков и пользователей и стала важным примером популяризации скандинавской мифологии.
Еще один пример перехода мифа в цифру — игра пермских инди-разработчиков Человеколось. За основу связи предания ханты, манси и саамов о лосе Ене и его семи сыновьях, которые каждый день отправляются в нижний мир, чтобы добыть щепотку солнца на следующий день мира среднего. По дороге можно собирать коллекцию пермского звериного стиля — гребни, заколки, бляхи — и неторопливо заваливать боссов из мифов — огромную щуку, хтонического медведя и эпического паука. Это точно интереснее краеведческих музеев!
Таким образом, успешная репрезентация определенного культурного знания в нашем мире происходит за счет цифры. Происходит не только переосмысление оригинальной истории, но и ее дополнение. Но это не самое главное. Главное — настало новое время цифры. Как некогда наступила эпоха «Галактики Гутенберга» с ее обширным книгопечатанием различного рода литературы, так сейчас наступила эпоха «Цифровой галактики». Теперь мы может не только воспринимать и осмыслять наше культурное наследие, но и перерабатывать его — подобно Лавкрафту, который превратил божество малых народов Южной части Тихого океана в ужасающего всех и вся бога Ктулху.
Денис Колобов

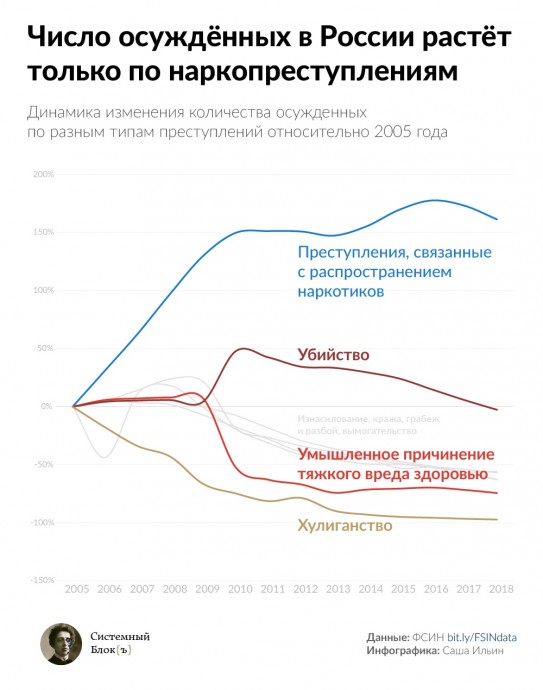
На сайте Федеральной службы исполнения наказаний РФ есть раздел с открытыми данными. Там опубликованы цифры по количеству осужденных за разные типы преступлений в динамике. Если эти данные верные, то единственная категория преступлений, по которой количество осужденных растёт — это преступления, «связанные с распространением наркотиков» (формулировка ФСИН). С 2005 года их стало больше в 2,5 раза.
Как видно из графика, в этот же период практически перестали сажать в тюрьму за хулиганство — падение почти 100%. Число осужденных за изнасилования, кражи, вымогательство, грабежи и разбой упало более чем вдвое.
На этом фоне рост наркопреступлений заставляет задуматься: действительно ли на общем фоне снижения преступности полиция стала ловить в 2,5 раза больше наркоторговцев? Алексей Кнорре из Института проблем правоприменения при Европейском Университете в Санкт-Петербурге ещё в 2017 году выяснил, что три четверти осужденных за наркопреступления — это потребители, а не распространители наркотиков. Такой перекос, по мнению исследователей — результат «палочной» системы в МВД, когда за отчетный период необходимо раскрыть плановое количество преступлений: выявлять потребителей значительно легче, чем распространителей.
Есть на графике и другие странности. Например, еще сильнее, чем грабежи и изнасилования, упало число осужденных за «умышленное причинение тяжкого вреда здоровью». Однако это падение выглядит искусственным: оно подозрительно совпадает со всплеском убийств. Есть вероятность, что одни и те же действия до 2009 года квалифицировали как умышленное причинение тяжкого вреда, повлекшее за собой смерть потерпевшего, а начиная с 2010 — как убийство.
Пока прозрачность ФСИН ограничивается несколькими датасетами, мы не можем уверенно говорить, что стоит за цифрами. Искать ответы придется по старинке журналистам и правозащитникам. Но открытые данные хороши уже тем, что позволяют видеть такие странности — и задавать неудобные вопросы. «Системный Блокъ» будет регулярно исследовать общедоступные датасеты — и визуализировать то, что заставляет задуматься.